
En l’espace de trois semaines, Anthropic a déroulé trois annonces qui dessinent assez clairement sa trajectoire pour 2026 : un nouveau modèle phare avec Claude Opus 4.7, une fonctionnalité de « rêve » pour les agents Claude, et un relèvement très attendu des limites d’usage de Claude Code adossé à un partenariat infrastructure avec SpaceX. Pris séparément, chaque sujet est intéressant. Mis bout à bout, ils racontent la même histoire : faire passer les agents IA de la démo au travail de production sur de longues durées.
Opus 4.7 : un Opus 4.6 plus rigoureux, pas une révolution
Disponible depuis le 16 avril 2026 sur l’ensemble des produits Claude et via l’API (référence claude-opus-4-7), Opus 4.7 est présenté par Anthropic comme une évolution directe d’Opus 4.6, à tarif identique : 5 $ par million de tokens en entrée, 25 $ en sortie. Le positionnement est clair : ce n’est pas le modèle le plus puissant du laboratoire — Mythos Preview, lié au programme Project Glasswing, conserve cette place — mais c’est aujourd’hui le modèle le plus avancé largement déployé.
Les gains revendiqués portent sur trois axes principaux :
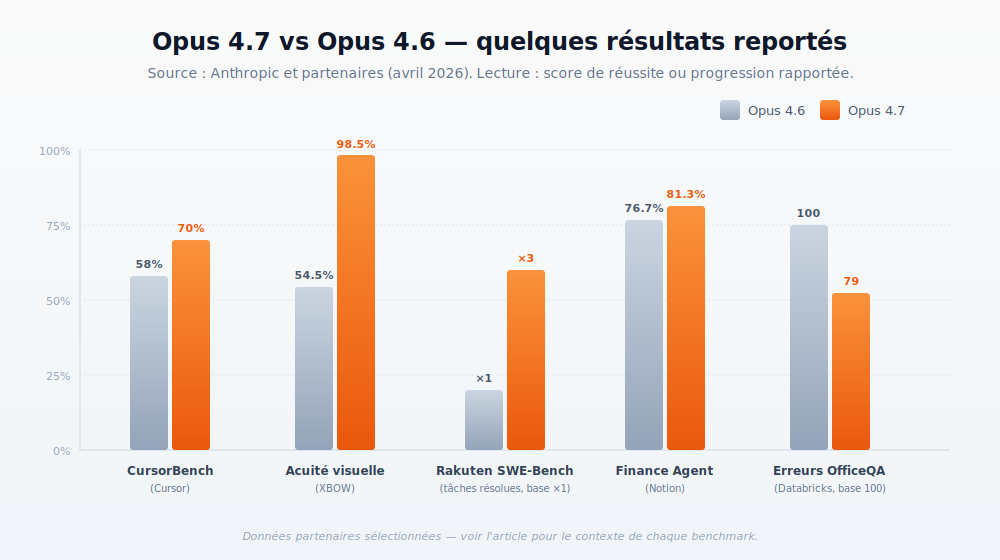
- Le code, en particulier sur les tâches longues et difficiles. Anthropic met en avant une meilleure planification, une attention accrue aux instructions, et la capacité du modèle à vérifier ses propres résultats avant de rendre la main. Plusieurs partenaires confirment : Cursor passe de 58 % à 70 % sur son benchmark interne, Rakuten rapporte trois fois plus de tâches résolues sur Rakuten-SWE-Bench, Notion mesure +14 % sur des workflows multi-étapes avec un tiers d’erreurs d’outils en moins.
- La vision haute résolution. Le modèle accepte désormais des images jusqu’à 2 576 pixels sur le grand côté (~3,75 mégapixels), soit plus de trois fois la résolution des Claude précédents. XBOW, qui fait de la pénétration automatisée par computer-use, parle d’un saut spectaculaire sur son test d’acuité visuelle (de 54,5 % à 98,5 %). Concrètement : screenshots denses, schémas techniques, structures chimiques, diagrammes d’ingénierie deviennent exploitables sans pré-traitement.
- La mémoire fichier. Opus 4.7 utilise mieux les notes persistées sur le système de fichiers entre sessions, ce qui réduit le contexte à recharger à chaque démarrage de tâche.
À noter, deux changements pratiques pour qui migre depuis Opus 4.6. D’abord, un nouveau tokenizer : le même texte produit 1,0 à 1,35 fois plus de tokens selon le contenu. Ensuite, un nouveau niveau d’effort xhigh, intercalé entre high et max, désormais réglage par défaut dans Claude Code. Le modèle « pense plus » aux niveaux élevés, donc consomme plus de tokens en sortie, en particulier sur les tours tardifs en mode agent. Anthropic recommande de re-tuner les prompts conçus pour les modèles précédents, qui interprétaient les instructions plus librement — Opus 4.7 les prend désormais au pied de la lettre.
Côté alignement, Anthropic décrit un profil similaire à Opus 4.6 : meilleur sur l’honnêteté et la résistance aux injections de prompt, légèrement plus laxiste sur certains conseils en réduction des risques liés aux substances contrôlées. Le modèle est jugé « largement bien aligné et digne de confiance, mais pas idéal ». Mythos Preview reste, selon les évaluations internes, le modèle le mieux aligné jamais entraîné par le laboratoire.
Le « rêve » des agents : consolidation de mémoire à la nuit tombée
Annoncée à la conférence Code with Claude début mai, la fonctionnalité Dreaming est la plus inhabituelle des trois. Elle ne touche pas le modèle lui-même, mais l’écosystème agent : Anthropic l’introduit dans son API Managed Agents, une infrastructure clé en main pour orchestrer des agents qui travaillent sur la même tâche pendant des minutes ou des heures.
Le problème qu’elle résout est concret. Quand un agent travaille longtemps, il prend des notes — préférences de l’utilisateur, commandes qui marchent, patterns de bug, choix d’architecture — et les écrit dans une mémoire persistante. Au fil des sessions, cette mémoire devient un dépôt brouillon : doublons, contradictions, entrées obsolètes. C’est exactement le genre d’entropie qui dégrade silencieusement la qualité d’un agent au bout de quelques semaines d’utilisation réelle.
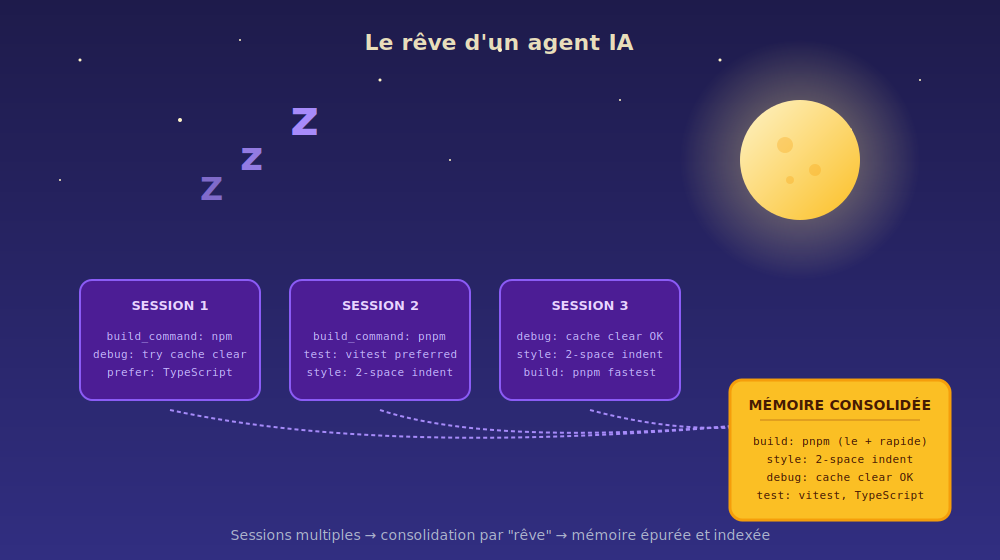
Le mécanisme du dream est simple à décrire et la métaphore biologique tient plutôt bien. À la demande, Claude lit le magasin de mémoire existant et un échantillon des transcripts de sessions passées, puis produit un nouveau magasin de mémoire reconstruit. Trois opérations sont effectuées : fusion des entrées dupliquées, remplacement des éléments obsolètes ou contradictoires par la valeur la plus récente, et extraction de patterns macros — récurrences d’erreurs, workflows convergents entre agents, préférences partagées par une équipe — qu’aucun agent isolé ne pouvait voir. Détail pragmatique important : la mémoire d’origine n’est jamais modifiée. Le résultat est un nouvel objet, qu’on peut comparer, valider ou jeter.
L’analogie avec le sommeil paradoxal n’est pas qu’un argument marketing. En neurosciences, le sommeil REM joue un rôle de consolidation : la mémoire à court terme accumulée dans la journée est rejouée, triée, intégrée à la mémoire à long terme. Sans ce cycle, on retient mal. Anthropic transpose explicitement cette idée — le nom de la fonctionnalité est revendiqué — pour résoudre un problème pragmatique d’ingénierie : un agent qui ne « dort » jamais accumule des notes sans jamais les consolider, et finit par s’auto-saboter.
La fonctionnalité est en research preview, accessible sur demande, et nécessite deux en-têtes beta dans les requêtes API : managed-agents-2026-04-01 et dreaming-2026-04-21. Les modèles supportés en aperçu sont Opus 4.7 et Sonnet 4.6. Anthropic prévient que des changements cassants peuvent survenir pendant l’aperçu, avec au moins une semaine de préavis.
Deux autres briques sont passées en bêta publique au passage. Outcomes permet de fournir un exemple de « bon résultat » pour une tâche : un grader agent distinct évalue la sortie de l’agent principal contre cet exemple. Utile sur les tâches qui exigent de l’exhaustivité ou une attention au détail. Multi-agent orchestration permet à un agent lead de découper un travail complexe et de déléguer les sous-tâches à des sous-agents, avec une console de traçabilité. Anthropic affirme avoir mesuré jusqu’à +10 points de réussite de tâche sur ses propres tests en combinant ces outils.
Claude Code : doublement des sessions, accord SpaceX et fin (partielle) des heures de pointe
Le 7 mai, Anthropic a annoncé trois changements sur les limites d’usage de Claude Code et de l’API. C’est la réponse — beaucoup plus appréciée que le retrait test de Claude Code du plan Pro le 21 avril, rétropédalé en 48 heures sous la pression — à un sujet devenu très sensible chez les développeurs : sessions qui s’arrêtent trop tôt, tokens qui partent vite, infrastructure qui peine à suivre la montée des usages agentiques.
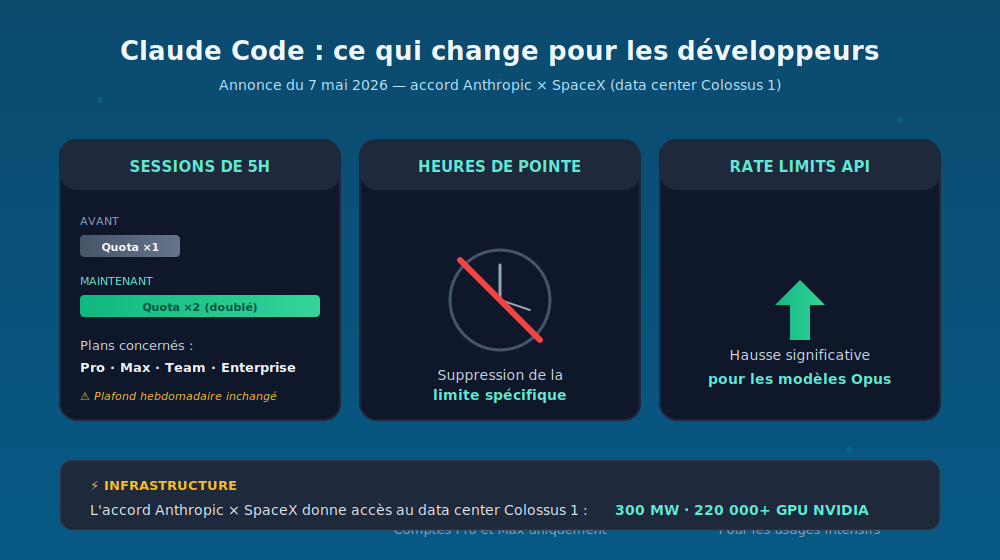
- Doublement des quotas pour les sessions de 5 heures sur les plans Pro, Max, Team et Enterprise. Mais — point important — les plafonds hebdomadaires ne bougent pas. On peut concentrer plus de travail dans une session ; on ne peut pas en faire significativement plus sur la semaine.
- Suppression de la limite spécifique aux heures de pointe sur Claude Code, pour les comptes Pro et Max. Pour ceux qui en avaient assez de voir leur productivité s’effondrer en milieu d’après-midi côte ouest, c’est la nouvelle la plus tangible.
- Hausse significative des rate limits de l’API sur les modèles Claude Opus. Pertinent pour les usages intensifs, les pipelines agentiques en production et les harnais de tests automatisés.
Ces marges supplémentaires ne sortent pas de nulle part. Elles sont rendues possibles par un nouvel accord avec SpaceX : Anthropic récupère l’intégralité de la capacité du data center Colossus 1, soit 300 mégawatts et plus de 220 000 GPU NVIDIA. Cet accord s’ajoute aux partenariats déjà en place avec Amazon, Google, Broadcom, Microsoft et NVIDIA. La capacité supplémentaire est activée immédiatement.
Pour les utilisateurs de l’interface web et mobile de Claude — les non-développeurs — la formulation officielle reste vague (« améliorera directement la capacité pour les abonnés Claude Pro et Claude Max ») et les limites sur les sessions de chat ne semblent pas modifiées. Le bénéfice direct est, à ce stade, réservé à ceux qui passent par Claude Code ou par l’API.
Ce que ces annonces racontent ensemble
Vu de loin, ces trois annonces convergent sur une même cible : l’agent qui tourne longtemps. Les améliorations d’Opus 4.7 — vérification de ses propres outputs, multimodal haute résolution, meilleure utilisation de la mémoire fichier — ne servent à grand-chose sur une question de chat. Elles deviennent essentielles quand l’agent enchaîne des dizaines d’étapes pendant des heures, doit lire des screenshots, et ne doit pas perdre le fil. Le dreaming attaque le même problème par l’autre bout : empêcher la mémoire d’un agent persistant de pourrir avec le temps. Et le doublement des quotas de session reconnaît, mécaniquement, que le travail réel ne tient pas en quelques minutes.
L’angle pédagogique pour le développeur ou l’analyste qui découvre ces sujets : les LLM grand public sont entrés dans une seconde phase. La première — celle de la complétion de phrase et du chatbot conversationnel — est largement résolue. La deuxième — celle de l’agent qui prend des décisions, manipule des outils et travaille sur la durée — soulève des problèmes très différents : tolérance aux erreurs d’outils, capacité à abandonner une mauvaise piste, gestion de mémoire à long terme, traçabilité des décisions. Anthropic, comme ses concurrents, est en train de construire l’infrastructure qui rend ces agents fiables. La fonctionnalité dreaming, en ce sens, est un signal faible intéressant : on ne fait pas dormir un modèle, on l’aide à oublier ce qui n’est plus pertinent. C’est un changement de problème.
Sources : Introducing Claude Opus 4.7 (Anthropic), Anthropic augmente les limites d’usage de Claude Code (Blog du Modérateur), documentation API Dreams (Anthropic), couvertures presse de la Code with Claude Conference.